Introduction to stacked generalization¶
Note
If you’re already familiar with stacked generalization, you can skip this part and go straight to the usage chapter, where we’ll discuss how to build stacked ensembles with Wolpert.
From the original paper, stacked generalization is “…a scheme for minimizing the generalization error rate of one or more generalizers. Stacked generalization works by deducing the biases of the generalizer(s) with respect to a provided learning set. This deduction proceeds by generalizing in a second space whose inputs are (for example) the guesses of the original generalizers when taught with part of the learning set and trying to guess the rest of it, and whose output is (for example) the correct guess” [W1992]. Basically what this means is training a set of estimators on a dataset, generating predictions off of them and training another estimator on those predictions. Here’s an example:
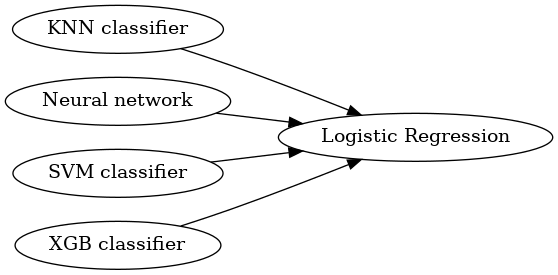
If you look at the image, it resembles a neural network. The edges may even have weights just like a neural network (check the transformer_weights parameter on the StackingLayer class) and also be deeper. The problem with stacked generalization is that, as models aren’t differentiable, we can’t train them using something like gradient descent. Instead, we build each layer one by one. To be able to generate a data set for the next layer on the model, we need to basically run a cross validation on the previous layer and use the predictions for the holdout sets as the new training set. The act of generating a new training set from the estimator’s cross validation predictions is called by some as blending [MLW2015]. There are several strategies for this step, so if you want to learn more about it, check the stacking strategies chapter.
Suppose we are building a stacked ensemble with two layers and the chosen blending method uses a 2-fold cross validation scheme. The basic algorithm is as follows:
- Split the training set in 2 parts;
- Train each estimator on the first layer using the first part of the training set and create predictions for the second part
- Train each estimator on the first layer using the second part of the training set and create predictions for the first part
- Use these predictions to train the estimators on the next layer
- Train each of the first layers estimators with the whole training set
The interesting part is the final estimator should perform at least as well as the best estimator used on the inner layers of our model [W1992].
Restacking¶
The stacked generalization framework is quite flexible, so we can play around with some architectures. One example that may help improve a stacked ensemble performance is restacking [MM2017]: we pass the training set unchanged from one layer to the other.
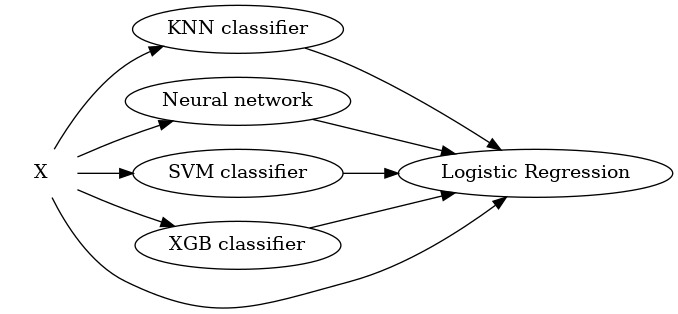
This may improve the stacked ensemble performance in some cases, specially for more complicated ensembles with multiple layers. A good example that uses multiple layers and restacking in practice is Kaggle’s 2015 Dato competition winner.
References
| [W1992] | (1, 2)
|
| [MLW2015] | Hendrik Jacob van Veen, Le Nguyen The Dat, Armando Segnini. 2015. Kaggle Ensembling Guide. [accessed 2018 Jul 16]. https://mlwave.com/kaggle-ensembling-guide/ |
| [MM2017] | Michailidis, Marios; (2017) Investigating machine learning methods in recommender systems. Doctoral thesis (Ph.D), UCL (University College London). |